- 배우기
-
블로그
- Babel
- Border
- Composer
- Coroutine
- Dagger
- Do it Kotlin Project
- ES6
- Flutter
- Fragment
- Memory
- Null safety
- Open Source
- Operator
- 개요
- Picasso
- Programming
- Project
- React
- RecyclerView
- Retrofit
- RxJava
- Tips
- Tools
- WSL
- Webpack
- cheat sheet
- collections
- podman
- 기초
- Amazon
- Android
- Angular
- Bootstrap
- Bootstrap 3
- DOM
- 드루팔
- Drupal7
- Fuse
- Hoisting
- HTML
- ionic
- Java
- Javascript
- jQuery
- JSON
- Layout
- Linux
- Motion Detect
- Nodejs
- PHP
- Primitive types
- React Native
- ReactJS
- Setting
- Ubuntu
- Views
- Web
- WebView
- Wordpress
- Kotlin
- 악보
Java Memory와 Android의 간략한 요약
일단 책의 34페이지에서 언급하는 메모리 모델은 일반적인 프로그램의 모델로 넣어둔 노트입니다. 너무 깊게 들어가면 입문서를 벗어나게 되므로 간략한 설명으로 끝내고 있죠. 좀 더 궁금한 분들을 위해 좀 정리해 보겠습니다.
고급 프로그래머가 되어갈 수록 또는 컴퓨터 프로그래밍을 하고 있는 한 이 메모리 문제는 여러분들이 자주 보게될 것입니다. 제일 잡기 어려운 버그도 메모리 관련 버그죠. 메모리는 OS, JVM, 아키텍처나 프레임워크의 운영 방식에 따라 모두 달라집니다. 따라서 모든 시스템에 완벽하게 메모리 최적화 한다는 것은 쉽지 않죠. 단, 메모리 누수와 같은 경우를 피할 정도의 개념을 갖춰야 할 것입니다.
프로그램의 일반적인 메모리
예전에는 주메모리로 사용하는 RAM이 640K 이하인 컴퓨터가 있었습니다. 그리고 누군가 이런 말을 했죠.
"메모리 640Kb면 충분하다!"
그 때의 PC의 프로세서로 8088이 시작되면서 그 유명한 x86계열의 PC가 시작됩니다. 이후 PC는 급격하게 발전하면서 640Kb의 장벽을 넘어서는 메모리 구조를 가져야 했고 메모리 보호모드등의 많은 개념들이 나오면서 현재는 PC가 64Gb를 주 메모리로 쓰는 경우가 있을 정도로 발전 했습니다. PC만은 못하지만 현대의 스마트폰도 예전에 비해 메모리가 아주 풍부합니다. 그렇다고 메모리를 마구 써댈 수는 없죠. 최적화는 여전히 필요합니다.
먼저 코틀린은 JVM, JS, Native상에서 동작할 수 있기 때문에 꼭 JVM메모리에 의존된 것은 아닙니다. 따라서 교재는 일반적인 프로그램의 메모리를 기준으로 설명되어 있고요. JVM상에서 동작할 때도 JVM 버전마다 조금씩 다르고 안드로이드의 ART에서 동작할 때 메모리 사용방법이 또 달라집니다. 이 모든 내용을 설명하면 꽤 어려워지므로 책은 간단한 개념만 설명하고 있습니다.

이 메모리 구조는 OS마다 조금씩 부르는 이름이 달라지지만 Heap과 Stack과 같은 개념을 거의 동일 합니다. 그 이외에 초기화된 데이터, 즉 전역변수나 Static 변수는 data에 들어가고 프로그램 실행과는 무관하게 이미 결정된 메모리로 구성됩니다. 실행전에도(파일내부에), 실행 중에도(메모리에), 종료할 때까지(메모리에서) 살아있죠. 자바는 모두 객체로 다루므로 알고리즘에 따라 PermGen이나 힙에 들어갈 수 있습니다.
만일 개별적인 스레드를 생성하는 경우에는 스레드만의 스택만 따로 가지게 됩니다.

자바의 메모리
자바의 메모리 구조는 많은 형태가 있겠지만 기본 개념은 같습니다. 크게 스택과 힙, 두개의 사용이 중요합니다. 이해를 돕기 위해 추가적으로 설명드리면 일반적인 자바의 JVM상에서 문자열을 사용하면
String s1 = "Hello";이것은 힙의 일부인 String pool에 들어가고
String s2 = new String("World");이것은 힙(Heap)에 생성되는 객체로 들어갑니다.
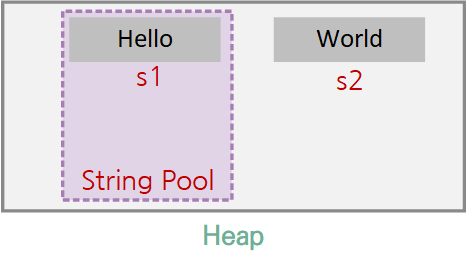
기본적으로는 String Pool에는 내용이 같은 객체 둘 이상 존재할 수 없습니다. 같은 내용의 변수 하나 더 만들면 동일한 주소가 사용됩니다. 그리고 일단 내용이 할당되면 그 크기가 고정되 수정할 수 없습니다. 하지만 JVM 버전과 설정에 따라 조금씩 달라질 수 있습니다.
String Pool 바깥에는 중복된 내용의 객체가 있을 수 있습니다. 내용이 자주 바뀌는 경우 크기와 내용을 새로운 객체 생성 없이 StringBuilder나 StringBuffer와 같은 것으로 임의 조정도 가능합니다.
String Pool의 크기는 JVM버전마다 조금씩 다르고 7에서는 JVM옵션에서 조정할 수 있습니다. 참조가 없으면 Heap이든 String Pool이든 GC 대상에 포함됩니다.
JVM의 메모리 종류를 좀 더 알아보면 다음과 같습니다.
JVM의 일반적인 메모리 구조

Heap
프로그램을 생성하면 구성되며 JVM 설정에 따라 크기가 결정될 수 있습니다. 객체들이 주로 할당되 사용되며 참조가 없으면 GC의 대상이 됩니다. 이 공간중에 새롭게 객체들을 생성된 것들은 Young Generation에 위치하고 오래된 것들은 Old Generation이라는 구역으로 나뉘어 배치되죠. 나중에 GC가 뭘 제거할 지 결정하게 됩니다.
Young Generation은 다시 Eden과 두개의 Survivor 메모리 공간으로 나뉩니다. Eden에 객체들이 채워지면 이제 GC가 살아남을 객체들을 Survivor 공간으로 옮깁니다. 이걸 다시 두번째 Survivor 공간에 옮기면서 항상 하나의 Survivor은 비워둡니다. 만일 객체들이 오랜 시간 살아남아 있다면 이제 Old generation으로 옮깁니다. 언제 옮길지는 특정 threshold 값을 지정할 수 있습니다.
Perm Gen
여기는 애플리케이션의 메타데이터가 저장됩니다. 여기는 힙(Heap)에 부분이 아닙니다. 사용되고 있는 애플리케이션의 클래스나 메서드의 정보로 구성됩니다. 만일 다음과 같이 구성하면 그 참조 주소가 Perm Gen에 저장되고 실제 객체는 힙에 들어갈 수 있습니다.
static Object o = new SomeObject();또한 static 멤버 변수들이 들어갈 수 있습니다. 예를 들어,
static int i = 1;와 같은 경우죠. 이때는 고정된 값을 가지게 됩니다.
Method area
여기는 Perm Generation의 일부로 주로 클래스, 메서드 데이터, 생성자나 필드 데이터가 구성됩니다. 또한, 클래스별로 Runtime constant pool이라는 공간을 실행될 때 만듭니다.
Memory Pool
Memory Pool은 불변값을 저장하는 공간으로 사용됩니다. 우리가 배운 String Pool이 이것에 의해 만들어집니다. 기본적으로Perm Gen에 구성될 수 있지만 Java 7에서는 JVM알고리즘에 따라 힙에 구성하기도 합니다. Perm Gen에 있었을 때는 영역크기 자체가 고정되므로 OOM(OutOfMemory) 문제가 비번하게 발생할 수 있었죠. Heap에 있으면 GC 대상에 들어가므로 String Pool의 내용도 GC에 의해 제거될 수 있습니다.
String s1 = "Hello";물론 코틀린에서 다음과 같이 지정된 경우 일반적으로 위의 코드로 변환됩니다.
val s1: String = "Hello"
JVM Stack
스택은 생성되는 스레드마다 개별적으로 가지게 됩니다 메서드의 결과, 반환 값을 저장하거나 임시 변수인 지역 변수 등을 담아두는데 사용합니다.
Native Method Stack
C스택이라고도 하고 자바에 의해 사용되지 않고 JVM 외부의 요소를 사용할 때 이용됩니다.
PC(Program Counter) Register
JVM에서 사용하는 다음 명령(Instruction)을 처리하기 위해 사용합니다.
GC(Garbage Collector)
몇가지 JVM의 정책 알고리즘에 따라 사용되지 않는 객체들을 수거합니다. 이것이 동작하는 시점을 프로그래머가 제어할 수 없었기 때문에 의도치 않은 굼뜬 현상이 일어나죠. GC가 일어난다는 것은 "무궁화 꽃이 피었습니다." 놀이와 비슷하게 앱에서 동작하던 모든 것을 멈추고 들여다봅니다. 예를 들어 데이터 화면을 스크롤 하다가 가끔 멈추는 등의 문제가 발생할 수 있습니다. 따라서 이 알고리즘은 버전마다 계속 개선되어 왔습니다. Young Gen. 영역은 비교적 빨리 제거되므로 크게 영향은 없지만 Old Gen.의 경우 살아남은 녀석 모두 살펴보느라 성능에 꽤 지장을 줍니다.
물론 명시적으로 System.gc()와 Runtime.gc()라는 메서드가 있긴 하지만 회수 시점은 다시 VM이 결정합니다. 단, 참조의 결합도에 따라 회수 방법의 알고리즘을 간접적으로 적용할 수 있습니다. 이때 사용하는 것이 Strong, Weak, Soft, PhantomReference라는 것이 있습니다.
따라서 제거되는 방법과 알고리즘이 지금까지도 개발되고 있고 JVM에 성능을 크게 좌우합니다.
안드로이드의 DVM/ART
구글의 경우 DVM(DalvikVirtualMachine)와 ART(AndroidRunTime) 를 설계하면서 이 부분을 좀 많이 뜯어 고쳤죠. 안드로이드가 가상머신을 사용하면서도 꽤 빠른 이유는 구글 개발자들이 상당히 많이 최적화 했다는 말이기도 합니다. 초반 안드로이드는 JVM을 그대로 사용했기 때문에 가상머신을 사용하지 않는 iOS에 비해 성능이 많이 떨어졌었죠. 지금은 DVM/ART 사용하면서도 iOS에서 제공되는 Native성능을 거의 동일하게 유지하죠. 그동안 하드웨어 스펙도 너무나 좋아져서 차이가 더 좁아진 것도 있지만 가상머신을 다시 만들 정도의 개선이 있었습니다.
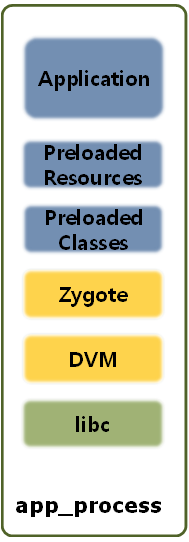
안드로이드의 DVM/ART는 리눅스의 Native 메모리 모델에 가깝게 설계되어 기존의 JVM메모리 관리기법을 많이 벗어났습니다. 이것은 기본적인 프로그램 메모리 모델인 code, data, heap(native), stack에 접근한다는 것이죠. 안드로이드의 커널은 리눅스이므로 리눅스의 페이징이나 메모리맵핑 기술을 적극 활용합니다. 여기서 Application은 code 영역에 해당하며 fork()된 후 각 앱에 맞춰 특정 부분으로 교체되어 사용됩니다. 미리 로드한 영역의 클래스나 리소스는 image heap으로 나타내기도 하는데 안드로이드 부팅 시 이미 로드되 결정됩니다. DVM은 아래있는 녹색은 Native 영역으로 C 라이브러리를 나타내는데 그밖에도 OpenGL과 같은 Native 라이브러리가 로드되어 있습니다. 여길 접근하려면 JNI(Java Native Interface)라는 것을 통해 들락날락 합니다. Native 라이브러리들은 Native의 Heap에 로딩됩니다. 여기는 반드시 프로그래머가 생성한 객체를 제거해 줘야 하죠.
안드로이드 앱이 사용하는 Heap은 DVM내에, 즉 가상머신 내부에 구성됩니다. JVM과 유사하게 DVM의 메모리가 구조화 되어 있으며 Heap을 GC가 관리하고 있습니다. 이렇게 Application 부분, 즉 머리에 해당하는 핵심 코드 부분은 제외한 나머지 부분이 Pool에 이미 구성되어 있어 실행할 때 그 부분만 교체됩니다.
하위 시스템 콜인 fork()를 사용하는 Zygote프로세스를 통해 앱의 메모리가 복제되며 일종의 풀을 가집니다. 레지던트 이블의 복제된 앨리스를 갖다 쓰듯이 앱의 구조를 미리 여러 개 만들어 놓았기 때문에 실행될 때 골라서 실행되며 아주 빠르게 메모리에 올라오죠. 또한 DVM의 JIT(Just In Time)에 의해 가상머신에서 코드를 실행할 때는 중간코드가 VM에 올라가 필요시 기계코드로 바뀌는 것이죠. 이것을 좀 더 빠르게 하기 위해 앱 실행 시 미리 특정 부분을 기계에 맞춰 바꾸는 기법입니다. 이후 ART의 AOT(Ahead of time) 컴파일을 도입하고 중간 코드가 아닌 해당 기계에 맞춰진 Native 기계코드를 아예 설치할 때 만드는 방법으로 앱 실행 능력을 키웠습니다. 이때 최대한 Native메모리를 활용합니다. 단, 초기 설치 시 약간 느린점과 기계코드를 가지므로 사이즈도 좀 더 커진 다는 단점은 있으나 하드웨어 스펙이 좋아지는 현대는 그렇게 크게 단점이 되는 것도 아닌 것 같습니다.
만일 시스템 메모리를 너무 많이 사용하고 있다면 안드로이드의 OOM(OutOfMemory) 관리자인 LMK(LowMemoryKiller)가 일어나 쓸모 없어 보이는 앱들을 일정 알고리즘에 의해 싹 제거해 줍니다. 리소스가 부족한 스마트폰에서는 자주 일어나는 일입니다.
프로그래머의 실수 중에 하나로 JVM기반에서 static 변수나 객체를 무한정 생성하다보면 Perm Gen이 모자라 금방 OOM에 도달하죠. 그래서 서드파티가 개발한 JVM중에는 이 영역이 없고 Native에 두기도 합니다.
좀 어려운 내용일 수 있으나 한번은 읽어보면 이해하는데 도움이 될 것입니다. 추후 계속해서 메모리 관련 이야기가 나오면 업데이트 해 두도록 하겠습니다. 그럼!
-
PREV[연재] 코틀린 프로젝트 - 02 - 3단계: 데이터의 구성과 RecyclerView의 어댑터
-
NEXT[연재] 코틀린 프로젝트 - 02 - 4단계: RxJava를 활용한 네트워크 서비스 비동기 태스크

Updated: 15 Jun 2019
Mobile Developer at Comparethemarket | Multiplatform | Full Stack | Kotlin, Flutter, Java, C/C++, Go, PHP
Related Contents

Language
Get in touch with us
"어떤 것을 완전히 알려거든 그것을 다른 이에게 가르쳐라."
- Tryon Edwards -